Data Loading and Processing Tutorial
http://pytorch.org/tutorials/beginner/data_loading_tutorial.html
Data Loading and Processing Tutorial
작성자: Sasank Chilamkurthy
어떠한 기계 학습 문제를 풀고자 할 때라도 데이터를 준비하는데 많은 노력이 들어갑니다. PyTorch는 데이터 로딩을 쉽게 하면서도 되도록이면 코드를 읽기 쉽게 하는 많은 도구들을 제공하고 있습니다. 이 튜토리얼에서는 어떻게 데이터를 읽어오고 어떻게 전처리하고 augment하는지를 볼 것입니다.
튜토리얼을 실행하기 위해 아래 패키지들이 설치되었는지 확인해봐야 합니다.
scikit-image: 이미지 입출력과 트랜스폼pandas: 쉬운 csv 파싱
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from __future__ import print_function, division import os import torch import pandas as pd from skimage import io, transform import numpy as np import matplotlib.pyplot as plt from torch.utils.data import Dataset, DataLoader from torchvision import transforms, utils # Ignore warnings import warnings warnings.filterwarnings("ignore") plt.ion() # interactive mode |
우리가 사용할 데이터셋은 얼굴 자세에 관한 데이터입니다. 얼굴에 다음과 같이 표시가 되어있습니다.

전체 다 해서 68개의 서로 다른 랜드마크 점들이 각 얼굴에 표시되어있습니다.
Note
데이터셋을 여기에서 다운받아 'faces/'라는 디렉토리 안에 이미지들이 들어가도록 하세요. 사실 이 데이터셋은 imagenet에서 'face'로 태그된 일부 이미지를 뽑아 dlib's pose estimation을 적용하여 생성한 것입니다.
데이터셋에는 다음과 같은 형식의 csv가 같이 따라옵니다.
|
1 2 3 4 |
image_name,part_0_x,part_0_y,part_1_x,part_1_y,part_2_x, ... ,part_67_x,part_67_y 0805personali01.jpg,27,83,27,98, ... 84,134 1084239450_e76e00b7e7.jpg,70,236,71,257, ... ,128,312 |
CSV 파일을 읽은 다음 점들을 꺼내 (N, 2) 크기 배열에 넣어놓습니다. 여기서 N은 랜드마크 점의 수입니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
landmarks_frame = pd.read_csv('faces/face_landmarks.csv') n = 65 img_name = landmarks_frame.iloc[n, 0] landmarks = landmarks_frame.iloc[n, 1:].as_matrix() landmarks = landmarks.astype('float').reshape(-1, 2) print('Image name: {}'.format(img_name)) print('Landmarks shape: {}'.format(landmarks.shape)) print('First 4 Landmarks: {}'.format(landmarks[:4])) |
Out :
이제 이미지와 랜드마크를 보여주는 간단한 헬퍼를 만들고 이를 이용해 샘플을 출력해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 |
def show_landmarks(image, landmarks): """Show image with landmarks""" plt.imshow(image) plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r') plt.pause(0.001) # pause a bit so that plots are updated plt.figure() show_landmarks(io.imread(os.path.join('faces/', img_name)), landmarks) plt.show() |
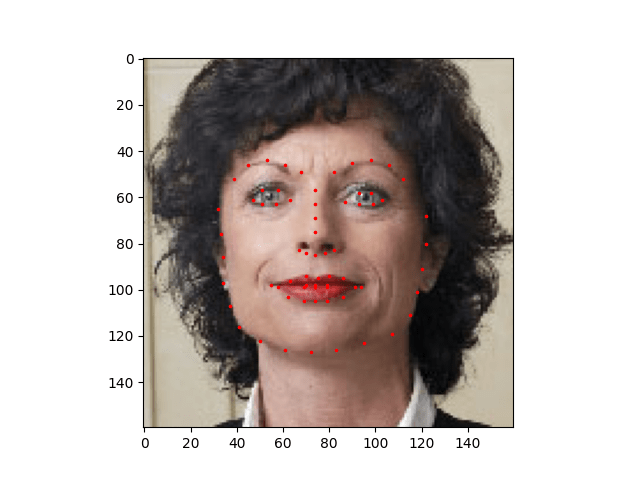
Dataset class
torch.utils.data.Dataset은 데이터셋을 제공하는 추상 클래스입니다. Dataset을 상속받아 다음 메소드들을 오버라이드 하여 커스텀 데이터셋을 만들 수 있습니다.
len(dataset)을 했을 때 데이터셋의 크기를 리턴할__len__dataset[i]을 했을 때 i번째 샘플을 가져오도록 하는 인덱싱을 위한__get_item__
이제 우리의 랜드마크 데이터셋을 위한 데이터셋 클래스를 만들어봅시다. __init__에서 csv를 읽어두겠지만 이미지는 __getitem__에서 읽도록 할 것입니다. 이는 메모리 효율성을 위해서인데, 모든 이미지를 메모리에 저장하지 않고 필요할 때에 한번 읽도록 위함입니다.
우리 데이터셋의 샘플은 dict로 {'image': image, 'landmarks': ladmarks}와 같은 형식이 될 것입니다. 또한 때에 따라 transform 매개변수를 받아 때에 따라 필요한 처리를 샘플에 적용할 수 있도록 할 것입니다. transform의 유용함은 다음 세션에서 보도록 합시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class FaceLandmarksDataset(Dataset): """Face Landmarks dataset.""" def __init__(self, csv_file, root_dir, transform=None): """ Args: csv_file (string): Path to the csv file with annotations. root_dir (string): Directory with all the images. transform (callable, optional): Optional transform to be applied on a sample. """ self.landmarks_frame = pd.read_csv(csv_file) self.root_dir = root_dir self.transform = transform def __len__(self): return len(self.landmarks_frame) def __getitem__(self, idx): img_name = os.path.join(self.root_dir, self.landmarks_frame.iloc[idx, 0]) image = io.imread(img_name) landmarks = self.landmarks_frame.iloc[idx, 1:].as_matrix() landmarks = landmarks.astype('float').reshape(-1, 2) sample = {'image': image, 'landmarks': landmarks} if self.transform: sample = self.transform(sample) return sample |
이제 이 클래스의 인스턴스를 만들고 데이터 샘플들을 하나씩 뽑아봅시다. 여기서는 처음 4개의 샘플과 그 랜드마크 점들을 출력하겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv', root_dir='faces/') fig = plt.figure() for i in range(len(face_dataset)): sample = face_dataset[i] print(i, sample['image'].shape, sample['landmarks'].shape) ax = plt.subplot(1, 4, i + 1) plt.tight_layout() ax.set_title('Sample #{}'.format(i)) ax.axis('off') show_landmarks(**sample) if i == 3: plt.show() break |

Out:
Transform
앞에서 살펴본 것에서 한가지 문제는 샘플이 모두 같은 크기가 아니라는 것입니다. 대부분의 신경망은 고정된 크기의 이미지를 가정합니다. 따라서 전처리 코드를 작성할 필요가 있습니다. 이제 트랜스폼을 만들어봅시다.
Rescale: 이미지를 리스케일RandomCrop: 이미지를 랜덤으로 크롭한다. 이는 데이터 augmentation이다.ToTensor: numpy 이미지를 torch 이미지로 변환 (축을 바꿀 필요가 있다.)
단순한 함수들 대신 호출할 수 있는 클래스로 구현할 것입니다. 그래서 transform을 실행할 때마다 파라미터를 넘기지 않도록 할 것입니다. 이를 위해서 __call__메소드를 구현하고, 필요하다면 __init__메소드 또한 구현할 것입니다. 이렇게 하면 다음과 같이 transform을 사용할 수 있게 됩니다.
|
1 2 3 |
tsfm = Transform(params) transformed_sample = tsfm(sample) |
위에서 설명한 transform을 이미지와 랜드마크에 어떻게 적용하는지 살펴봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
class Rescale(object): """Rescale the image in a sample to a given size. Args: output_size (tuple or int): Desired output size. If tuple, output is matched to output_size. If int, smaller of image edges is matched to output_size keeping aspect ratio the same. """ def __init__(self, output_size): assert isinstance(output_size, (int, tuple)) self.output_size = output_size def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] h, w = image.shape[:2] if isinstance(self.output_size, int): if h > w: new_h, new_w = self.output_size * h / w, self.output_size else: new_h, new_w = self.output_size, self.output_size * w / h else: new_h, new_w = self.output_size new_h, new_w = int(new_h), int(new_w) img = transform.resize(image, (new_h, new_w)) # h and w are swapped for landmarks because for images, # x and y axes are axis 1 and 0 respectively landmarks = landmarks * [new_w / w, new_h / h] return {'image': img, 'landmarks': landmarks} class RandomCrop(object): """Crop randomly the image in a sample. Args: output_size (tuple or int): Desired output size. If int, square crop is made. """ def __init__(self, output_size): assert isinstance(output_size, (int, tuple)) if isinstance(output_size, int): self.output_size = (output_size, output_size) else: assert len(output_size) == 2 self.output_size = output_size def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] h, w = image.shape[:2] new_h, new_w = self.output_size top = np.random.randint(0, h - new_h) left = np.random.randint(0, w - new_w) image = image[top: top + new_h, left: left + new_w] landmarks = landmarks - [left, top] return {'image': image, 'landmarks': landmarks} class ToTensor(object): """Convert ndarrays in sample to Tensors.""" def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] # swap color axis because # numpy image: H x W x C # torch image: C X H X W image = image.transpose((2, 0, 1)) return {'image': torch.from_numpy(image), 'landmarks': torch.from_numpy(landmarks)} |
Compose transform
이제 샘플에 transform을 적용해봅시다.
이미지의 가로, 세로 중 짧은 쪽의 크기를 256으로 리스케일한 뒤, 크기 224의 정사각형으로 랜덤 크롭을 하고 싶다고 하자. 다시 말하면 Rescale과 RandomCrop transform을 조합해보도록 합시다.
torchvision.transforms.Compose는 이러한 작업을 하기 위한 callable 클래스입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
scale = Rescale(256) crop = RandomCrop(128) composed = transforms.Compose([Rescale(256), RandomCrop(224)]) # Apply each of the above transforms on sample. fig = plt.figure() sample = face_dataset[65] for i, tsfrm in enumerate([scale, crop, composed]): transformed_sample = tsfrm(sample) ax = plt.subplot(1, 3, i + 1) plt.tight_layout() ax.set_title(type(tsfrm).__name__) show_landmarks(**transformed_sample) plt.show() |
Iterating through the dataset
이제 transform 조합을 포함하여 모든 기능을 넣은 데이터셋을 만들어봅시다. 요약하자면, 데이터셋은 다음을 샘플링합니다.
- 이미지를 즉성에서 파일로부터 읽어들인다.
- 읽은 이미지를 트랜스폼한다.
- 트랜스폼이 랜덤하게 이루어지기 때문에 데이터는 샘플링할 때 augmentate된다.
전에 본 것처럼 데이터셋은 for i in range로 방문할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv', root_dir='faces/', transform=transforms.Compose([ Rescale(256), RandomCrop(224), ToTensor() ])) for i in range(len(transformed_dataset)): sample = transformed_dataset[i] print(i, sample['image'].size(), sample['landmarks'].size()) if i == 3: break |
Out:
하지만 for루프를 사용해서 모든 데이터에 대해 반복하면 많은 특별한 기능을 사용하지 못합니다. 특히 다음을 못하게 됩니다.
- 데이터의 배치(batch)
- 데이터의 셔플링
multiprocessing워커를 통한 병렬 데이터 로드
torch.utils.data.Dataloader는 이러한 기능을 제공하는 iterator입니다. 아래 예제처럼 간결한 파라미터를 사용합니다. 한가지 흥미로운 파라미터는 collate_fn입니다. collate_fn을 사용하면 샘플이 얼마나 정확히 배치될 필요가 있는지 정할 수 있습니다. 하지만 대부분의 경우 기본 collate도 잘 작동합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
dataloader = DataLoader(transformed_dataset, batch_size=4, shuffle=True, num_workers=4) # Helper function to show a batch def show_landmarks_batch(sample_batched): """Show image with landmarks for a batch of samples.""" images_batch, landmarks_batch = \ sample_batched['image'], sample_batched['landmarks'] batch_size = len(images_batch) im_size = images_batch.size(2) grid = utils.make_grid(images_batch) plt.imshow(grid.numpy().transpose((1, 2, 0))) for i in range(batch_size): plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size, landmarks_batch[i, :, 1].numpy(), s=10, marker='.', c='r') plt.title('Batch from dataloader') for i_batch, sample_batched in enumerate(dataloader): print(i_batch, sample_batched['image'].size(), sample_batched['landmarks'].size()) # observe 4th batch and stop. if i_batch == 3: plt.figure() show_landmarks_batch(sample_batched) plt.axis('off') plt.ioff() plt.show() break |

Out:
Afterword: torchvision
지금까지 데이터셋과 transform, dataloder를 어떻게 만들고 사용하는지 알아보았습니다. torchvision 패키지는 공통적으로 사용되는 데이터셋과 transform들을 제공합니다. 커스텀 클래스를 작성하지 않아도 될 수도 있습니다. 한가지 torchvision에서 기본으로 사용할 수 있는 데이터셋은 ImageFolder입니다. 이는 이미지가 다음과 같이 들어있다고 가정합니다.
|
1 2 3 4 5 6 7 8 9 10 |
root/ants/xxx.png root/ants/xxy.jpeg root/ants/xxz.png . . . root/bees/123.jpg root/bees/nsdf3.png root/bees/asd932_.png |
여기서 'ants', 'bees' 등은 클래스 레이블입니다. 비슷한 기본 transform으로 PIL.Image와 같이 작동하는 RandomHorizontalFlip, Scale등도 있습니다. 다음처럼 dataloader를 만들때 같이 사용할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import torch from torchvision import transforms, datasets data_transform = transforms.Compose([ transforms.RandomSizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train', transform=data_transform) dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset, batch_size=4, shuffle=True, num_workers=4) |
학습하는 코드와 함께 있는 예제는 튜토리얼 Transfer Learning tutorial을 참고하면 됩니다.