하루에도 수만개의 글자를 읽고 있습니다. 하루에도 수백장의 종이를 들춰 읽습니다.
이것은 그 읽기에 대한 일기입니다.
Fully Convolutional Networks for Semantic Segmentation
2월 2nd, 2021 Posted by 룬룬
Problem
CNN의 발전은 이미지 분류 뿐 아니라 박스 기반의 객체 검출에도 좋은 결과를 가져왔다. 자연스럽게 다음 단계로의 확장으로서 각 픽셀들에 대한 prediction을 하는 행위를 생각할 수 있다.
Essense
End-to-end로 학습되고 pixels-to-pixels로 추가 작업 없이 작동되는 Fully convolutional network (FCN)을 제안하였다.
FCN은 어떤 입력 크기를 넣어도 dense한 출력을 낼 수 있고, 또한 dense한 전체 이미지의 입출력으로 learning과 inference가 가능하다.
FCN은 다른 방법들이 patchwise로 학습하는 것에 반하여 별도의 전처리, 후처리가 필요 없어 효율적으로 동작한다.
이 모델은 clasification 문제를 fully convolution으로 다시 해석하여 dense prediction을 구현한 것이다.
Segmentic segmentation은 global 정보와 local 정보를 모두 사용하기 위해 skip 구조를 사용하여 local-to-global pyramid 내에 encode된 feature들을 deep, coarse, semantic 정보들을 통합하였다.
Detail
Convnets을 구성하는 연산들은 일종의 non-linear 함수들로 볼 수 있다. 예를 들면 convolution이나 average pooling, spatial max, elementwise nonlinearity 등을 예로 들 수 있다.
만약 어떤 신경망이이러한 nonlinear 함수들로만 이루어져 있다면, 이를 deep filter 혹은 fully convolutional network라고 부르고자 한다. 이러한 FCN은 어떤 크기의 입력에서도 출력을 낼 수 있다.
따라서 sptial dimensions의 각 위치에 대해 loss function이 정의되므로 이미지 전체에서 발생하는 loss 들은 일종의 minibatch처럼 작동하여 stochastic gradient descent와 동일한 효과를 가져온다. 같은 이유로 receptive field가 서로 충분히 겹칠 경우, patch를 따로 학습시키는 것보다 더 효율적이다.
Adpating classifiers for dense prediction
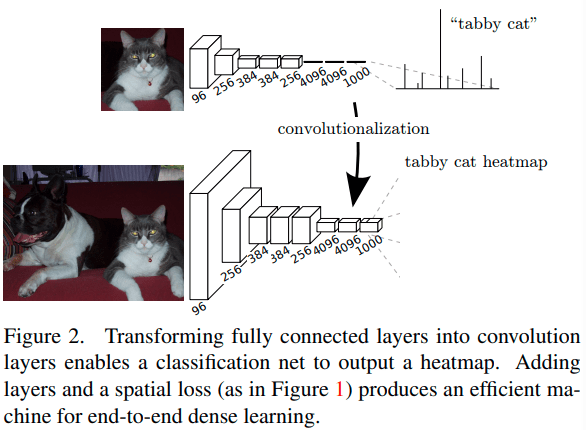
기존의 recognition에서 사용하는 구조는 고정된 입력 크기를 받고, nonspatial한 출력을 내놓는다. Fully connected layer의 입력은 고정된 차원을 갖고 이를 통과하면서 지역적인 정보는 사라지게 된다.
하지만 이 역시 전체 입력 feature의 크기와 동일한 크기의 커널을 갖는 convolution으로 생각할 수 있고, 이러한 컨셉을 적용하면 다른 크기의 이미지 또한 입력할 수 있게 된다.
심지어 이미지를 패치로 만들어 따로 연산하는 것보다 더 빠르게 계산할 수 있다.
이러한 특징들은 semantic segmentation에 적용하기에 적절하였다. 각 출력 셀마다 GT를 할당하여 직접 학습을 시켜버렸다.
단 네트워크 내의 subsampling으로 인하여 실제 출력은 입력 크기보다 작아지며 이는 receptive field의 stride와 일치하는 factor를 가진다.
Shift-and-stitch if filter rarefaction
Input shifting and output interlacing은 coarse한 출력에서 dense한 prediction을 얻는 트릭으로 OverFeat에서 사용한 방법이다.
다운샘플된 factor가 f라고 한다면, 입력 이미지를 x축 y축으로 0에서 f만큼 shift시킨 입력을 개 생성한다. 이를 convnets에 입력하면 interlaced된 출력을 얻을 수 있다. receptive field의 중심이 조금씩 다르기 떄문이다.
이 interlaced된 출력을 통합하면 원래 해상도의 결과가 된다.
이런 과정을 레이어 수준에서 재현하기 위해 stride로 줄여지는 만큼 결과를 upsample하여 다음 레이어로 진행시킬수도 있으나, 출력이 정확하게 같지는 않을 것이다. 기존의 filter가 이미 줄어든 영역의 입력을 받도록 학습되어있기 때문이다.
때문에 upsample된 입력에서 원래의 filter의 계산에 참여하지 않는 위치는 0으로 만들어준 새로운 필터를 고안할 수 있다. 이 새로운 필터를 subsampling이 사라질 때 까지 모든 레이어에 적용하면 동일한 결과를 얻을 수 있다.
이 방법은 fine한 정보를 갖긴 하지만 작은 receptive field를 갖게 되고 계산도 오래 걸린다. 마찬가지로 shift-and-stitch 트릭 또한 receptive field의 저하 없이 dense한 결과를 얻지만 fine한 정보를 얻기 힘들게 된다.
따라서 논문의 모델에는 이를 적용하지 않기로 하고 더 나은 방법을 이용하였다.
Upsampling is backwards strided convolution
Coarse한 출력을 dense한 픽셀로 연결시키는 방법으로 단순한 interpolation을 생각할 수 있다
이런 맥락에서 factor f의 upsampling은 stride 1/f의 입력을 갖는 일종의 convolution으로 생각할 수 있고, 이는 결국 output stride f의 backwards convolution 혹은 deconvolution이다.
사실 deconvolution filter의 weight가 고정될 필요는 없으므로 학습이 가능하다.
심지어 deconvolution 레이어와 activation 함수를 쌓으면 nonlinear upsampling이 되어버린다.
실험에서 빠르고 효과가 좋았기 때문이 이를 사용하였다.
Patchwise training is loss sampling
전체 이미지를 fully convolutional 하게 학습하는 것은 모든 이미지의 receptive field에 해당하는 패치 전체를 batch로 하여 학습하는 것과 동일하면서도 시간적으로 효율적이다.
패치 기반 학습에서 랜덤 샘플링을 통해 loss를 제한하고자 하는 것은 DropConnect mask 등의 방법을 통해 같은 효과를 낼 수 있다.
패치 기반 학습은 또한 클래스간 불균형을 수정할 수 있는데, FCN에서 이는 각 위치의 loss에 weight를 주는 것으로 같은 효과를 볼 수 있다.
Segmentation Architecture
AlexNet, GoogLeNet, VGG-16을 골라 이를 수정하였다. GoogLeNet은 마지막 average pooling 레이어를 제거하였다.
공통적으로 마지막 classfier 레이러를 제거하고 fully connected layer를 convolution으로 교체하였다. 1x1 convolution을 붙여 PASCAL의 21개 클래스에 대한 score를 prediction 하도록 하였다.
다음 deconvolution 레이어로 bilinearly upsample을 하여 원래의 해상도로 맞춰주었다.
이렇게 학습한 결과는 나름 괜찮았지만 결과가 상당히 coarse 하였다.
이를 해결하기 위해 마지막 prediction 레이어와 finer한 stride를 갖는 이전 레이어를 연결시켜 주는 방법을 사용하였다. 이 방법으로 global한 structure를 반영할 수 있도록 하였다.
해상도에 따라 FCN-32s, FCN-16s, FCN-8s 3가지 종류의 네트워크를 만들 수 있었다.